Choosing the right open-source Large Language Model (LLM) can feel like navigating a maze. Today, we simplify things by staging a direct, head-to-head comparison between two major players in a very similar weight class: Xiaomi’s MiMo-7B and Alibaba’s Qwen3-8B. With MiMo packing around 7 billion parameters and Qwen3 at roughly 8.2 billion, this is a “fair fight” – comparing cutting-edge, efficient models of comparable scale.

Common Ground: Where They Align Architecturally
Before we explore their differences, let’s establish their shared foundation. Both MiMo-7B and Qwen3-8B leverage modern transformer architectures and boast several similarities:
- Size & Depth: They operate in the same parameter ballpark (~7B vs ~8.2B) and both utilize 36 transformer layers.
- Efficient Attention: Both employ Grouped Query Attention (GQA). This technique cleverly reduces memory usage and speeds up processing, especially beneficial when dealing with long sequences of text.
- Flexible Embeddings: They both use untied embeddings, meaning the model uses separate parameters for understanding input words and generating output words, potentially offering more nuance.
- Rich Vocabulary: Expect large vocabularies (150,000+ tokens) from both, allowing them to effectively handle diverse languages, specialized symbols (like math notation), and programming code.
This common architecture means they start from a similar place in terms of raw complexity. However, their distinct training philosophies and feature sets make them excel in different areas.
Performance & Specialization Focus
Here’s where MiMo-7B and Qwen3-8B carve out their unique identities.
MiMo-7B: The Reasoning & Coding Specialist
Xiaomi didn’t just build an LLM; they explicitly engineered MiMo-7B for elite reasoning, particularly in mathematics and code generation.
- Targeted Prowess: Xiaomi highlights MiMo-7B’s ability to outperform significantly larger models (even those in the 30B+ class) on challenging math and coding benchmarks. It was built to rival specialized systems in these domains.
- Training Strategy: The model underwent rigorous training involving vast amounts of math and code data, followed by Reinforcement Learning (RL) fine-tuning focused on achieving verifiable correctness in solutions.
- Who Needs This? If your project demands exceptional accuracy in solving complex equations, generating logical proofs, or writing clean, functional code, MiMo-7B is tailor-made. It’s designed for deep, rigorous thinking within these specific, structured domains.

Qwen3-8B: The Powerful & Versatile Generalist
Qwen3-8B is no slouch in reasoning or code either, demonstrating strong performance comparable to other top 8B models. However, its true strength lies in its impressive breadth and versatility.
- Multilingual Mastermind: Trained on an enormous dataset covering 119 languages and dialects, Qwen3-8B is exceptionally skilled at translation, cross-lingual tasks, and serving diverse global user bases.
- Conversational & Knowledgeable: It excels in general knowledge tasks and instruction following, making it great for building chatbots, summarizing information, and engaging in creative writing. It’s designed for natural, human-like interaction.
- Agent Capabilities: Qwen3 models emphasize tool use. Qwen3-8B integrates well with frameworks for building AI agents that can interact with external APIs, databases, or other tools to accomplish tasks.
- Who Needs This? If you require a robust all-rounder that handles conversations smoothly across many languages, understands complex instructions, works well with external tools, and still delivers solid reasoning and coding performance, Qwen3-8B offers that powerful, balanced package.

Handling Information: The Context Window Challenge
An LLM’s “memory” or context window determines how much information it can consider at once.
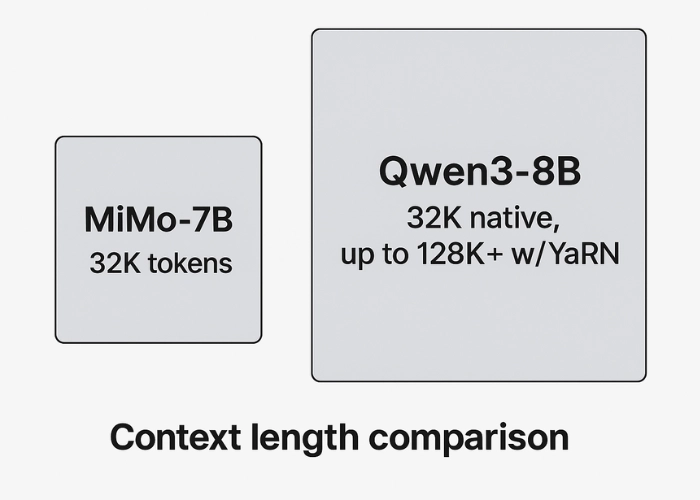
- Standard Capacity (32K Tokens): Both MiMo-7B and Qwen3-8B comfortably handle a 32,768-token context window natively. This is sufficient for many tasks involving reasonably long documents or chat histories.
- Qwen3-8B’s Ultra-Long Reach (128K+): This is a major differentiator. Qwen3-8B is specifically designed and validated to extend its context dramatically, up to 128,000 tokens (or slightly more) using a technique called YaRN.
- Why YaRN Matters: It’s a smart way for the model to effectively process truly massive amounts of text – think entire codebases, lengthy research papers, or very long ongoing conversations – without getting lost or degrading significantly in quality.
- The Verdict: While MiMo-7B’s 32K is good, Qwen3-8B’s proven ability to handle 4x that amount gives it a significant edge for tasks demanding deep comprehension of extensive texts.
Inference Flexibility: Choosing Speed vs. Depth
How quickly do they generate responses, and can you adjust their “thinking process”?
- Baseline Speed: Given their similar architectures, their fundamental token-generation speed is expected to be in the same league.
- MiMo-7B’s Potential Edge: MTP: MiMo was trained with Multiple-Token Prediction (MTP), a technique aimed at predicting several tokens ahead, which can potentially lead to faster overall inference speeds in optimized environments.
- Qwen3-8B’s Unique Feature: Thinking Modes: Qwen3 offers a fascinating dual-mode capability, often controllable via prompts in supported frameworks:
- Non-Thinking Mode (Default): Optimized for speed and efficiency, delivering direct answers quickly. Ideal for standard chat or simple queries.
- Thinking Mode: Activates a deeper, internal step-by-step reasoning process (like Chain-of-Thought) before providing the answer. This boosts accuracy for complex math, logic, or coding problems but comes at the cost of higher latency and resource use.
- The Verdict: MiMo might be inherently faster due to MTP optimizations. Qwen3 provides unparalleled flexibility, letting you choose between speed or depth dynamically based on the task’s complexity.
Resource Requirements
Despite their impressive abilities, both models are relatively resource-friendly for their capability level.
- VRAM Needs (Very Similar): They require nearly identical amounts of GPU memory:
- MiMo-7B: ~14-16 GB VRAM (using 16-bit precision).
- Qwen3-8B: ~16-18 GB VRAM (using 16-bit precision).
- Quantization is Key: Both models are excellent candidates for quantization. Running them at lower precision (e.g., 4-bit or 8-bit) dramatically cuts VRAM usage, often allowing them to run smoothly on consumer GPUs with as little as 8 GB VRAM, and can also improve speed.
Key Takeaway: Don’t let the “Billion parameters” scare you. With quantization, both models are accessible on reasonably powerful consumer hardware. Their resource needs are not a major differentiating factor between them.
Practical Tests Between Mimo 7B and Qwen 8B
1. Decimal Comparison
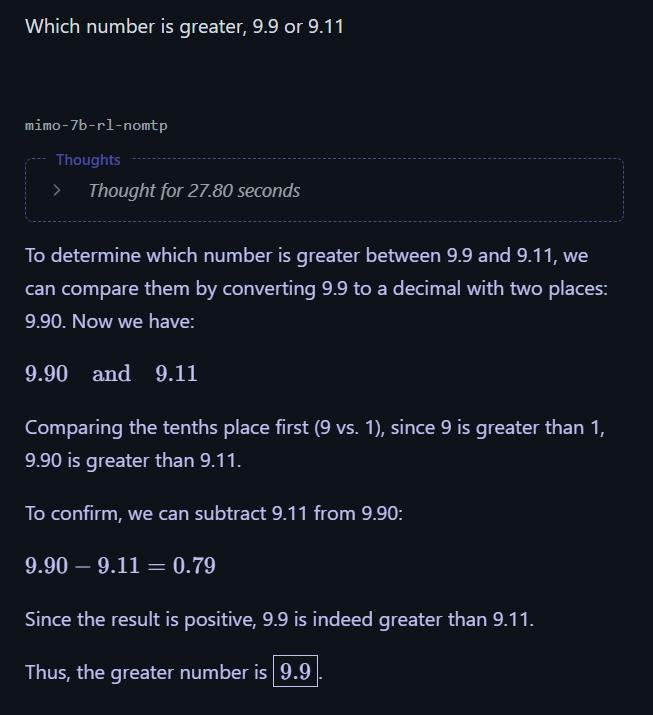
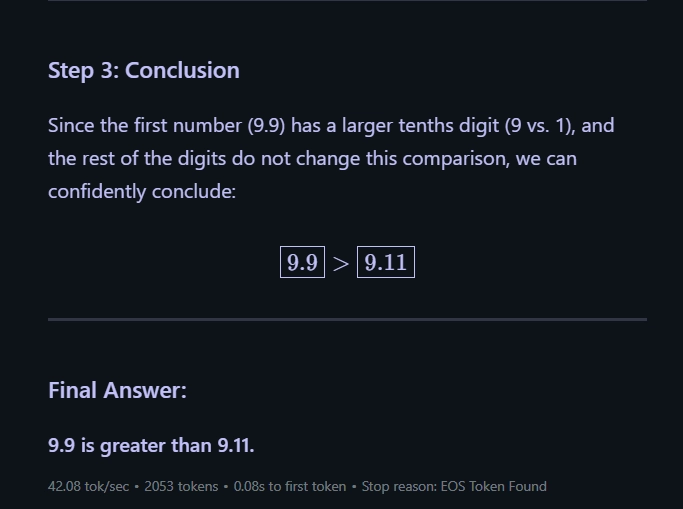
Question: Which number is greater, 9.9 or 9.11?
Answer: 9.9
Mimo 7B: Correct
Qwen 8B: Correct
2. Temporal Trick Question
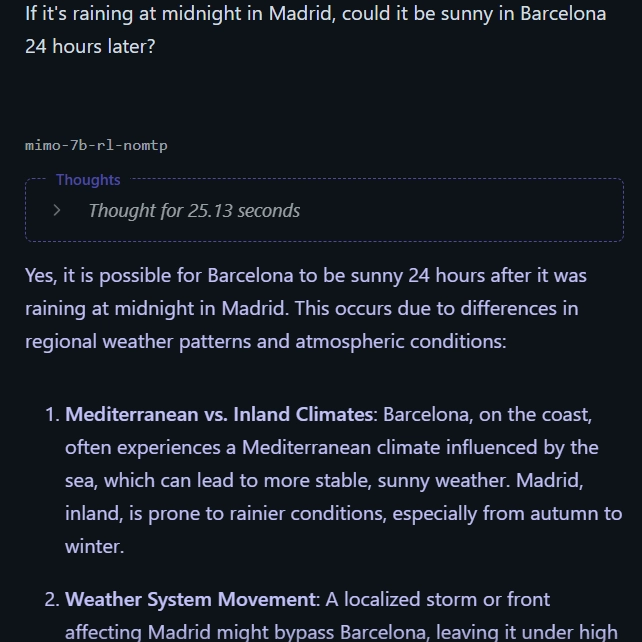
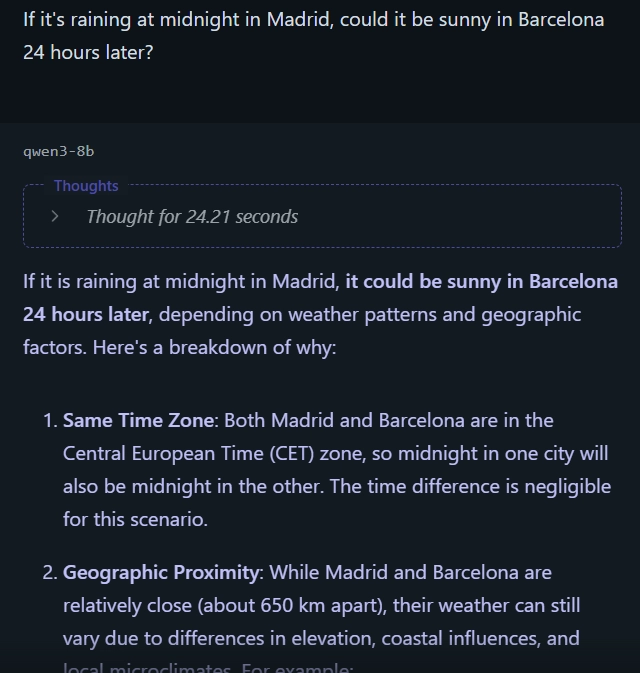
Question: If it’s midnight in Madrid and raining, could it be sunny in Barcelona 24 hours later?
Answer: No—24 hours later is still midnight, so it can’t be sunny.
Mimo 7B: Incorrect
Qwen 8B: Incorrect
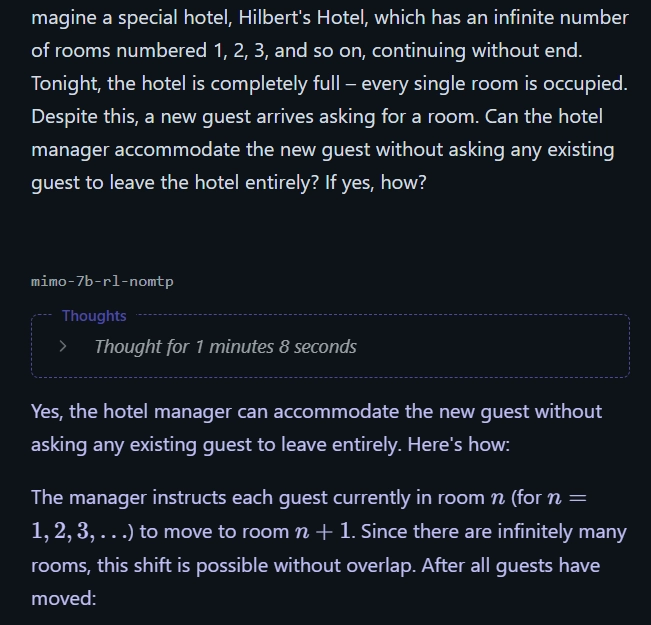
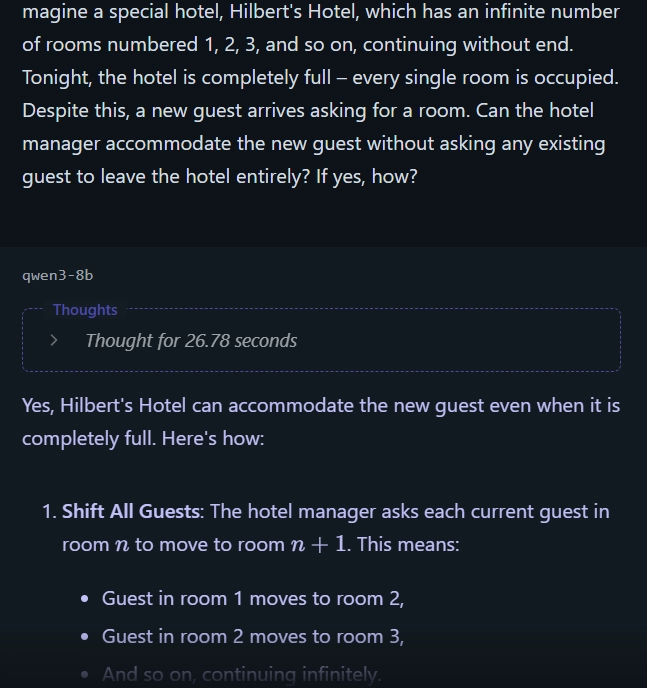
3. Hilbert’s Hotel
Question: Imagine Hilbert’s Hotel with infinitely many occupied rooms. Can it take in a new guest without asking anyone to leave?
Answer: Yes—ask each guest in room n to move to room n + 1.
Mimo 7B: Correct
Qwen 8B: Correct
4. HTML Web-Page Prototype
Task: Generate a complete HTML page.
Mimo 7B: Minimal skeleton
Qwen 8B: Detailed template with semantic tags, CSS placeholders and responsive nav
Making the Choice: Which Model Fits Your Use Case?
Let’s distill it down to the core decision points:
Choose Xiaomi MiMo-7B if:
- ✅ Your project’s success hinges on state-of-the-art accuracy in mathematical reasoning or code generation.
- ✅ You prioritize a model specifically trained and fine-tuned for verifiable logical correctness.
- ✅ Potential inference speed boosts via MTP are attractive.
- ✅ A 32K context window fully meets your requirements.
Choose Alibaba Qwen3-8B if:
- ✅ You need a highly capable, versatile all-rounder for diverse tasks (chat, multilingual, reasoning, code, summarization).
- ✅ Handling ultra-long documents or conversations (up to 128K tokens) is essential.
- ✅ You value the flexibility to switch between fast responses and deep reasoning (Thinking Mode).
- ✅ Robust multilingual support (119+ languages) is a key requirement.
- ✅ You plan to build AI agents that interact with external tools.
- ✅ You prefer the widely adopted Apache 2.0 license.
Final Verdict: Specialist Rigor or Versatile Powerhouse?
Ultimately, MiMo-7B and Qwen3-8B cater to slightly different philosophies, even at similar sizes.
- If your goal is uncompromising excellence in specific, logic-driven domains like advanced math or complex coding, and 32K context suffices, MiMo-7B offers that specialized, deeply trained rigor.
- If you need a powerful, adaptable model that excels across the board – from nuanced conversation in many languages to processing enormous texts and acting as an intelligent agent – Qwen3-8B provides that broader capability set and flexibility.
Both are stellar examples of how far efficient open-source LLMs have come. By understanding their unique strengths outlined here, you can choose the 7B/8B-class model that truly aligns with your vision and propels your AI application to success.